第一部分:执行摘要:2025年 Kotlin Multiplatform 最终评估
2025年,Kotlin Multiplatform (KMP) 已经毫无疑问地成为一项成熟且可用于生产环境的技术,尤其在Android与iOS应用之间共享业务逻辑方面。其来自JetBrains和Google的双重战略支持 ,已经巩固了它作为该领域一流解决方案的地位。对于在2025年考虑采用KMP的团队而言,最关键且最微妙的决策已不再是“是否能用”,而是“如何架构用户界面(UI)”。
近期,Compose Multiplatform for iOS的稳定版发布 ,为开发者开辟了两条截然不同但均可行的路径:
- 共享逻辑,原生UI (The Pragmatic Approach):一种灵活的、原生优先的策略,仅共享非UI部分的业务逻辑,而UI层则由各个平台的原生技术(Android的Jetpack Compose/XML,iOS的SwiftUI/UIKit)独立构建。
- 共享逻辑与UI (The Unified Approach):一种追求高效率的统一策略,使用Compose Multiplatform将业务逻辑和UI代码一并共享。
这一选择对团队结构、开发体验、最终产品的用户体验(UX)乃至项目风险管理都具有深远的影响。本报告将深入剖析KMP生态系统的现状,对这两种UI策略进行详尽的比较分析,并提供一个可操作的决策框架,旨在为技术决策者在进行这项重大的技术投资时提供清晰、有据可依的指引。
第二部分:平台现状:核心技术与战略支持
要评估一项技术的成熟度,首先必须审视其底层基础的稳定性以及来自行业领导者的战略承诺。在2025年,KMP在这两方面都表现出前所未有的强势。
2.1 K2编译器与Kotlin 2.2:构建于速度与现代性之上的基础
KMP的性能和开发效率在2025年得到了根本性的提升,这主要归功于K2编译器的全面落地和Kotlin语言本身的持续进化。
- K2编译器成为默认选项:从IntelliJ IDEA 2025.1版本开始,K2编译器已成为默认选项 。这不仅仅是一次版本更新,而是一次对编译器架构的彻底重写。JetBrains内部一个包含超过1200万行Kotlin代码的巨型项目,在切换到K2模式后,构建时间缩短了40% 。这一成就直接解决了跨平台项目长期以来的痛点之一:缓慢的编译和持续集成(CI)流程,极大地提升了开发生产力。
- Kotlin 2.2语言新特性:随着Kotlin 2.2.0成为最新的稳定版本 ,一系列新的语言特性,如
when表达式的守卫条件(guard conditions)和上下文参数(context parameters),进一步增强了代码的安全性和表达力 。这意味着开发者可以编写出更健壮、更易于维护的共享业务逻辑。同时,2.2.20的Beta版本已经发布 ,显示出JetBrains正以极快的节奏进行迭代和优化。
2.2 2025年路线图:双轨并行的市场策略
JetBrains为KMP制定的2025年路线图清晰地展示了一种双轨并行的市场渗透策略,旨在满足不同类型团队的需求,从而最大化其市场接受度。
- 第一轨道:“全栈Kotlin”路径与Compose Multiplatform:JetBrains的首要任务是将Compose Multiplatform for iOS打造成一流的稳定解决方案。2025年的工作重点包括:实现与Jetpack Compose的功能对等、优化iOS端的渲染性能,以及完善导航、资源管理、无障碍(Accessibility)和国际化等核心功能 。在KotlinConf 2025上正式宣布其稳定,是整个生态系统的一个里程碑事件 。
- 第二轨道:“务实集成”路径与Swift导出:与此同时,JetBrains正在积极开发一种直接将Kotlin代码导出为Swift模块的机制,目标是在2025年发布首个公开版本 。该工具旨在提供与现有Objective-C桥接相当的用户体验,同时克服后者的种种限制,例如能更好地处理可空类型、泛型和枚举,使Swift调用Kotlin代码时感觉更自然、更符合语言习惯 。
这种双轨策略并非摇摆不定,而是对市场需求的深刻洞察。它允许KMP同时吸引两个截然不同的用户群体:一是追求最大化代码复用和统一开发流程的初创公司或Android背景浓厚的团队(Compose Multiplatform路径);二是拥有庞大且对原生工具有着深厚执念的iOS团队的大型企业(Swift导出路径)。这种灵活性是KMP相较于Flutter等“全有或全无”框架的显著竞争优势。通过提供一个低摩擦的集成选项,KMP有效地降低了在复杂组织中推广的阻力。
2.3 Google的官方背书:从实验到生产级支持
如果说JetBrains的努力是KMP发展的内生动力,那么Google的官方支持则为其注入了强大的外部可信度。
- 官方支持与生产应用:在Google I/O大会上,Google正式宣布为KMP提供支持,特别是用于在Android和iOS之间共享业务逻辑 。这并非空头支票,Google已将自家的旗舰应用,如Google Docs,在iOS端投入使用KMP进行生产环境的运行,并报告其性能与之前相比持平甚至更优 。这种规模的应用实践为KMP的稳定性、性能和可扩展性提供了最有力的证明。
- Jetpack库的多平台化:Google正在投入大量资源,将核心的Jetpack库进行多平台化改造。目前,包括Room(数据库)、DataStore(数据存储)、Paging(分页加载)、ViewModel(视图模型)在内的多个关键库已经发布了支持iOS的稳定版本 。这对开发者而言是一个颠覆性的改变,因为它意味着团队可以在共享代码中直接使用那些他们在Android开发中早已熟悉、功能强大且经过大规模实战检验的架构组件。
下表总结了KMP技术栈中关键组件在2025年的成熟度状态,为技术决策者提供了一个清晰的概览。
表2.1:KMP技术栈成熟度 (2025年)
| 组件 | 状态 | 2025年关键里程碑 | 相关资料来源 |
| Kotlin语言 (K2) | Stable | K2编译器成为IDE默认选项,显著提升构建速度 | |
| KMP核心框架 | Stable | 已在众多大型应用中得到生产验证 | |
| Compose Multiplatform for iOS | Stable | API稳定,正式发布,可用于生产环境 | |
| Compose Multiplatform for Desktop | Stable | 已稳定,广泛用于桌面应用开发 | |
| Compose for Web (Wasm) | Beta | 性能和API对等性持续改进,向Beta阶段迈进 | |
| Kotlin-to-Swift 导出 | Experimental | 计划2025年发布首个公开版本 | |
| Amper 构建工具 | Experimental | 2025年重点支持KMP移动应用开发 |
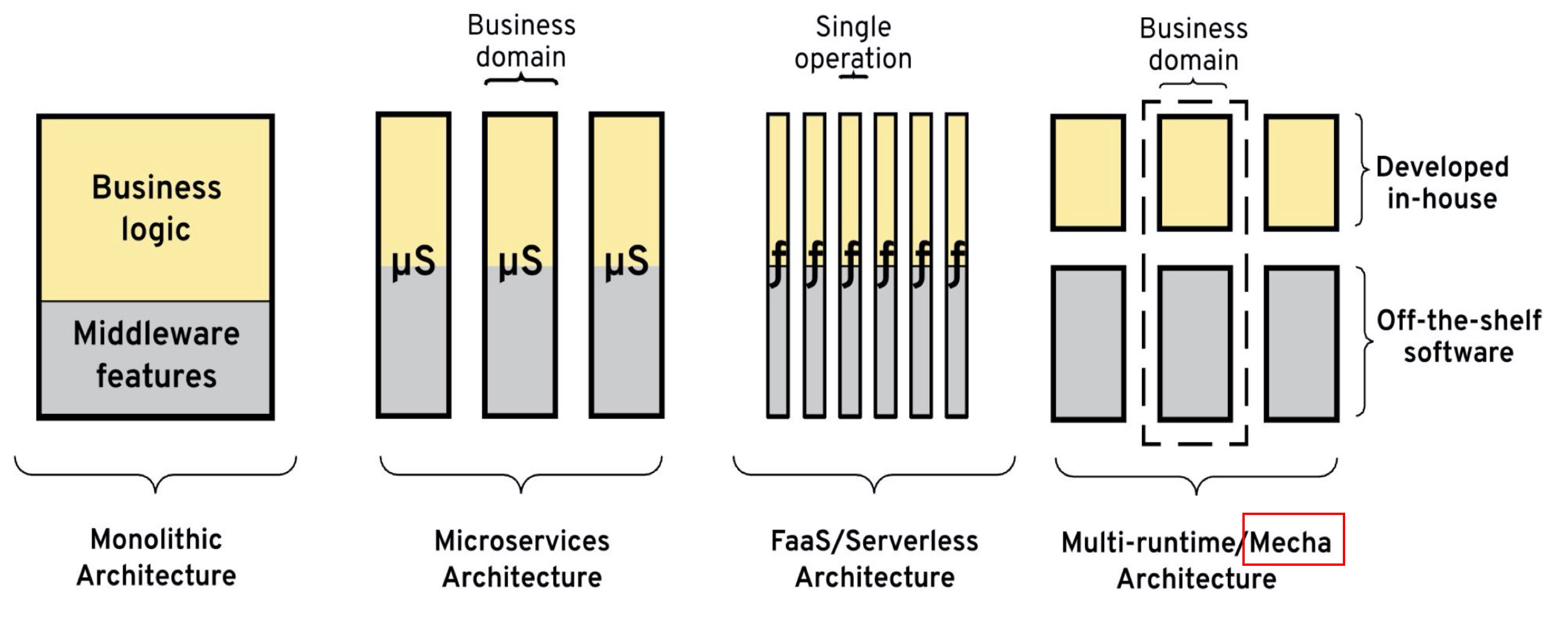
第三部分:核心决策:用户界面(UI)的架构选择
在确认KMP核心技术已然成熟之后,团队面临的最关键决策便是如何处理UI。2025年,两条路径都已清晰且可行,但它们各自通往截然不同的开发模式和产品形态。
3.1 策略一:共享逻辑,原生UI(务实主义路径)
这种模式是KMP最经典、风险最低的应用方式,它将代码共享的边界严格限制在非UI层面。
- 架构解析:该模型的核心是创建一个共享的Kotlin模块,其中包含所有的业务逻辑、数据层(网络请求、数据库访问)、状态管理等。然后,在此之上构建两个完全独立的、100%原生的UI层:Android端使用Jetpack Compose或传统的XML,iOS端则使用SwiftUI或UIKit 。当共享代码需要调用平台特有的API(如传感器、文件系统、加密算法)时,通过KMP提供的
expect/actual机制来实现,这允许在共享模块中定义一个期望的(expect)接口,然后在各个平台模块中提供实际的(actual)实现 。 - 优势分析:
- 极致的原生保真度:UI/UX是完全原生的,可以完美地遵循各平台的设计规范、交互习惯和动画效果,确保用户获得最流畅、最地道的体验,不存在任何“非原生感” 。
- 发挥团队专长:允许Android和iOS的专家团队继续使用他们最擅长的工具链(Android Studio/Compose, Xcode/SwiftUI),最大程度地减少了学习成本和文化摩擦 。
- 低风险的增量迁移:对于已有的原生应用,这是理想的迁移路径。团队可以从共享一小部分逻辑开始(例如一个复杂的算法或网络层),然后逐步扩大共享范围,风险完全可控 。
- 挑战与开发体验:
- “两个团队,一个大脑”的协作难题:此模式的成败高度依赖于团队间的无缝协作。如果Android和iOS团队处于孤岛状态,很容易出现“逻辑分叉”的问题:iOS开发者可能会因为共享模块过于“Android中心化”或难以使用,而选择在Swift中重写逻辑,这便完全违背了KMP的初衷 。
- 状态管理的互操作性:将Kotlin现代的状态管理模式(如
StateFlow)转换为SwiftUI能够方便消费的形式,并非易事。如果没有清晰的架构约定和良好的封装,这里很容易成为产生摩擦和bug的重灾区 。 - iOS端的调试困境:从Xcode中调试共享的Kotlin代码至今仍是一个挑战,断点功能可能不稳定。这常常迫使iOS开发者将共享模块视为一个“黑盒”,严重影响了生产力,也增加了他们重写逻辑的动机 。
- 案例深度剖析:
- Netflix:在其内部使用的Prodicle工作室应用中,Netflix利用KMP共享了平台无关的业务逻辑、网络层(使用Ktor)和数据持久化(使用SQLDelight),尤其是在需要强大离线支持的场景下,同时保持UI完全原生 。
- Forbes:共享了超过80%的业务逻辑,这使得他们能够在两个平台同步推出新功能,同时保留了根据平台特性定制原生UI的灵活性 。
- McDonald’s:共享了应用内支付等复杂功能的逻辑。在KotlinConf 2025上,他们展示了一个关键的创新:将导航逻辑(即决定在何种条件下从哪个屏幕跳转到哪个屏幕)也放入了KMP共享模块,而UI界面和导航控制器本身仍然是原生的 。
3.2 策略二:共享逻辑与UI,采用Compose Multiplatform(统一化路径)
随着Compose Multiplatform for iOS的稳定,这条追求极致代码复用的路径变得切实可行。
- 架构解析:在这种模式下,一个单一的Kotlin代码库不仅包含业务逻辑,还包含了使用Compose Multiplatform编写的声明式UI代码 。这套共享的UI代码在Android上通过Jetpack Compose渲染,在iOS上则通过一个宿主
UIViewController嵌入,并利用原生的图形库进行绘制 。 - 优势分析:
- 最大化代码复用:可以实现高达95%甚至更高的代码共享,极大地减少了开发和维护的工作量,避免了“一份需求,两份实现”的资源浪费 。
- 提升开发速度:由于无需在两个平台上分别编写和同步UI代码,新功能的交付速度得以大幅提升。这对于开发MVP(最小可行产品)、内部工具,或者那些品牌视觉一致性高于平台原生性的应用来说,优势尤为明显 。
- 统一的团队结构:可以组建一个单一的Kotlin开发者团队来负责两个平台的开发,简化了团队管理和知识传递。例如,Physics Wallah公司通过此举将Android和iOS工程师整合成了一个统一的移动团队 。
- 挑战与“稳定版”的现实: Compose for iOS的“稳定”主要指API的稳定性,为生产使用提供了保障。然而,开发者在实际项目中仍会遇到一些挑战 :
- UI/UX的一致性问题:目前Compose Multiplatform缺少一套原生的“Cupertino”风格组件库,导致所有组件默认呈现Material Design风格,这在iOS上可能会显得格格不入。尽管滚动物理效果、文本处理等方面已经对齐了iOS的原生行为 ,但要让所有组件都达到完美的iOS原生质感,仍需大量的自定义工作 。
- 性能与调试:虽然应用的启动时间与原生应用相当 ,但在复杂的UI界面上,开发者报告了布局卡顿(jank)、CPU占用率高和内存泄漏等问题。此外,由于Xcode的视图调试工具无法检查Compose的视图层级,可视化调试变得非常困难 。
- 无障碍功能(Accessibility):将Compose视图正确地暴露给iOS的无障碍服务,目前仍存在一些挑战,可能会影响特殊用户群体的使用体验 。
- 案例深度剖析:
- Bitkey by Block:这家公司最初采用了原生UI的策略,但后来主动迁移到了Compose Multiplatform。其核心原因并非技术瓶颈,而是组织效率:在一个没有严格区分iOS/Android专家的精干团队中,频繁在Jetpack Compose和SwiftUI之间切换上下文,既繁琐又容易出错。统一的UI代码库提升了他们对功能一致性的信心,并简化了开发流程 。
- Feres & WallHub:这两个应用报告称使用Compose Multiplatform共享了90-100%的UI代码,充分展示了该策略在代码复用方面的巨大潜力 。
技术决策的核心,往往是在不同类型的风险之间进行权衡。在KMP的UI策略选择上,这一点体现得淋漓尽致。选择“原生UI”路径,意味着将赌注押在团队的协作和架构能力上,它最小化了产品/UX风险(保证了最佳用户体验),但最大化了执行/团队风险。一旦团队协作出现问题 ,其所有优势都将荡然无存。反之,选择“共享UI”路径,则最小化了
执行/团队风险(简化了开发流程和团队结构),但引入了产品/UX风险。团队可能会交付一个在iOS上感觉不够“地道”的应用,从而影响用户观感和接受度。
因此,这个决策并非纯技术问题,而是要求技术领导者对团队文化、技能储备和项目目标进行综合评估。
表3.1:UI策略决策矩阵 (KMP原生UI vs. Compose Multiplatform)
第四部分:开发者生态:工具、库与社区
一项技术能否在实际项目中成功落地,其周边的生态系统——包括开发工具、可用的库和社区支持——起着决定性的作用。
4.1 开发环境:IDE与构建工具
- IDE的统一:目前,KMP的开发体验已经全面整合到开发者熟悉的IntelliJ IDEA和Android Studio中 。JetBrains已经调整了策略,不再将实验性的Fleet IDE作为KMP的主要开发环境,而是加倍投入于完善基于IDEA的工具链 。官方的KMP插件提供了项目创建向导和集成化工具,尽管一些开发者仍然认为,与纯原生开发相比,其流程中还存在一些摩擦点 。
- 构建系统的挑战:Gradle:Gradle是当前官方指定的构建工具。然而,它的复杂性是一个被广泛承认的痛点,特别是对于不熟悉JVM生态的开发者(例如大多数iOS开发者)而言。多平台的Gradle配置可能相当复杂,并且是导致构建失败的常见原因 。
- 构建系统的未来:Amper的承诺:JetBrains正在开发一个名为Amper的实验性项目。这是一个专为Kotlin和JVM设计的、更为简洁的构建工具。2025年的重点目标就是使其能够完全支持包含共享UI的KMP移动应用开发 。Amper的存在本身就是对Gradle复杂性的承认,它预示着未来KMP项目的配置体验将得到极大的改善。
4.2 库生态景观:两大生态的融合
KMP的库生态系统在2025年呈现出前所未有的强大,这得益于两个成熟生态的交汇。
- 成熟的Kotlin原生库生态:由JetBrains和社区主导开发的核心库已经非常成熟且可用于生产。这包括用于并发的
kotlinx.coroutines、用于JSON序列化的kotlinx.serialization、用于网络编程的Ktor,以及用于本地数据库的SQLDelight。这些库构成了绝大多数KMP项目的基石。 - 颠覆性的Jetpack多平台库生态:Google承诺将Jetpack库多平台化,是近年来KMP生态最重要的发展。像
Room、DataStore、Paging和ViewModel这样的库,现在已经为iOS提供了稳定(Tier 1级别)的支持 。这意味着团队可以在共享代码中使用与Android开发完全相同的、功能强大、文档齐全且经过实战检验的架构组件。 - 分级支持模型:必须清楚地认识到,Jetpack库的支持是分级的。Android、iOS和JVM属于Tier 1级别,意味着得到了全面的测试和支持。macOS和Linux等桌面平台属于Tier 2级别(部分测试)。而Web/Wasm则属于Tier 3级别(实验性) 。这意味着,虽然KMP在移动端的故事非常强大,但如果要扩展到其他平台,就需要仔细核对所需库的支持级别。
KMP生态系统的力量源于两个强大库生态(Kotlin自身和Android Jetpack)的融合,但其当前的短板在于将它们粘合在一起的工具(Gradle)。JetBrains显然已经认识到Gradle的陡峭学习曲线是阻碍KMP被更广泛采用(尤其是在非JVM背景的iOS开发者中)的主要瓶颈。因此,Amper项目是一个旨在降低入门门槛、平滑开发者体验的战略性举措。对于2025年的决策者来说,当前的工具链可以被视为一个“充满挑战但正在改善”的现状,并且已经有了一条官方明确支持的、通往更美好未来的道路。
表4.1:关键Jetpack多平台库对iOS的支持情况 (2025年)
注:版本号基于截至2025年8月1日的数据 。
第五部分:性能、架构与团队动态
一个成功的技术选型不仅要看其功能,还要评估其非功能性表现以及对团队组织结构的影响。本部分将探讨KMP在实际运行中的性能、构建可维护应用的架构模式,以及成功实施所必需的“人”的因素。
5.1 性能画像:原生设计
KMP的性能优势根植于其核心设计理念:将代码编译为目标平台的原生二进制文件(Android为JVM字节码,iOS为基于LLVM的原生代码) 。这意味着共享的业务逻辑是以原生速度运行的,这与那些依赖于JavaScript桥接的框架形成了鲜明对比,后者在复杂计算或高频交互时可能成为性能瓶颈 。
- 基准测试数据:与React Native相比,KMP应用在基准测试中展现出更优的性能。其启动时间快约30%,内存消耗低15-20%,电池消耗也减少了10-15% 。
- UI性能:当采用“原生UI”策略时,UI性能与完全原生的应用完全相同 。当采用“共享UI”(Compose Multiplatform)策略时,对于大多数场景,性能表现良好且与原生应用相当。然而,如前所述,在处理极其复杂的UI或长列表时,可能会遇到需要特别优化的性能问题,如卡顿或CPU占用过高 。
5.2 架构最佳实践:构建长青应用
社区在长期的实践中,已经沉淀出了一套行之有效的KMP架构模式。
- 整洁架构 (Clean Architecture):这是KMP社区中最主流的架构模式。它倡导将应用清晰地划分为不同的层次(如领域层、数据层、表现层),这与KMP将共享逻辑与平台特定UI分离的理念完美契合 。
- 多模块结构:对于大型项目,强烈建议采用多模块的组织方式,而不是将所有代码都放在一个庞大的
shared模块中。可以按功能划分模块(如core-network,feature-login,feature-dashboard),这有助于改善编译速度、提高代码的可维护性,并支持团队并行开发 。 expect/actual模式的审慎使用:这是KMP实现平台互操作性的关键机制。最佳实践是将其严格限制在架构的边界处(例如,在数据层提供平台特定的数据库驱动或网络客户端实现),以此来封装平台差异,避免平台相关的细节泄漏到核心业务逻辑中 。
5.3 人的因素:团队结构与协作
KMP项目最常见的失败原因并非技术本身,而是组织和协作上的障碍。
- 最大的风险:团队孤岛:一种注定会失败的模式是:Android团队负责开发共享模块,然后像“扔过墙”一样将其交给iOS团队使用 。
- “黑盒”反模式:这种孤岛式的协作方式,会导致iOS团队将KMP模块视为一个不透明、不可信的第三方依赖。当遇到问题时,他们无法或不愿去调试Kotlin代码,最终选择在Swift中重写逻辑,从而使KMP的优势荡然无存 。
- 成功的模式:统一的移动团队:成功的KMP实践需要文化的转变。像Physics Wallah这样的公司,已经将其Android和iOS工程师整合成一个统一的“移动团队” ,共同对整个代码库负责。
- 协作最佳实践:
- 共同所有权:Android和iOS开发者都必须对共享模块负责。这可能需要对iOS开发者进行Kotlin/Gradle的培训,或者在处理共享代码相关的任务时采用结对编程 。
- 清晰的架构契约:共享模块与原生UI之间的接口必须被良好地定义和文档化,并避免做出“Android中心化”的假设 。
- 同理心与沟通:向团队推广KMP需要充分理解各平台专家的顾虑。JetBrains官方甚至提供了详细的指南,指导如何管理这一过渡过程,包括解释采用KMP的“原因”,以及创建概念验证项目来展示其价值 。
KMP不仅仅是一项技术,它更像是一个组织变革的催化剂。它迫使团队重新审视移动开发的协作模式。一个项目的成功,在很大程度上不取决于代码写得如何,而取决于协作模式是否有效。一个技术领导者在考虑KMP时,不仅要为开发时间做预算,更要为组织变革管理(如培训、工作坊、团队重组)预留资源。对KMP投资的回报率,与跨团队协作的水平成正比。忽视人的因素,是导致失败的最大预兆。
第六部分:竞争格局与最终建议
为了做出最终决策,我们需要将KMP置于更广阔的跨平台市场中进行比较,并综合所有分析,给出一套明确的建议。
6.1 KMP vs. Flutter vs. React Native:2025年战略快照
这三个框架并非简单的优劣之分,而是代表了三种不同的开发哲学和应用场景。
- Kotlin Multiplatform:“务实的”原生派。它最适合那些希望在保留100%原生UI/UX控制权的同时共享业务逻辑的团队,或者是那些寻求使用Compose技术栈实现最大化代码复用的团队。其核心优势在于性能和灵活性 。
- Flutter:“统一的”UI派。它最适合用单一代码库构建视觉效果丰富、高度定制化的UI。其核心优势在于UI一致性和UI密集型应用的开发速度 。
- React Native:“Web到移动”的桥梁。它最适合拥有现有JavaScript/React技术栈的团队。其核心优势在于庞大的生态系统和对于Web开发者极低的入门门槛 。
表6.1:KMP vs. Flutter vs. React Native:2025年战略快照
6.2 最终建议与项目准备清单
KMP在2025年的最终价值主张在于其战略灵活性。它是唯一一个不强迫开发者采用“一刀切”模式的主流框架。它允许企业根据自身需求,选择代码共享的程度——从共享10%(一个核心算法)到共享95%(全部逻辑和UI),并允许这种策略随着产品和团队的演进而动态调整。这种适应性降低了被单一技术路线锁定的风险。
在2025年,您的团队应该采纳Kotlin Multiplatform,如果:
- 您的应用拥有复杂且关键的业务逻辑,必须在各平台间保持高度一致(例如金融、健康、物流领域) 。
- 您正在计划迁移一个现有的大型原生应用,并需要一条低风险、可增量实施的代码共享路径 。
- 您的团队已经拥有深厚的Kotlin/Android开发经验,这将极大地降低学习成本 。
- 性能和真实的原生外观感受是不可妥协的需求(这将引导您选择“原生UI”策略) 。
- 您是一个初创公司或一个优先考虑开发速度的团队,并且愿意拥抱完整的Compose Multiplatform技术栈(这将引导您选择“共享UI”策略) 。
您应该持谨慎态度或选择其他方案,如果:
- 您的应用极其简单,主要以UI展示为主,几乎没有复杂的共享逻辑 。
- 您的首要目标是以最快速度推出一个简单的MVP,且团队拥有强大的Web开发背景(在这种情况下,React Native的初始开发速度可能更快) 。
- 您的组织内部,移动开发团队之间壁垒森严,存在强烈的协作抵触文化(这是采用KMP的最大危险信号) 。
总而言之,Kotlin Multiplatform在2025年已经发展成为一个强大、灵活且得到行业巨头支持的成熟技术。它为那些希望在代码复用带来的效率和原生应用提供的卓越体验之间找到最佳平衡点的团队,提供了一个无与伦比的解决方案。它并非适用于所有场景的“银弹”,但对于合适的项目和团队而言,它无疑是通往未来跨平台开发的一条坚实路径。